
Consider finding the minimum of the following function of two variables, starting at some random point:
We could do so by adjusting each of the two parameters in the direction that would move downhill along the surface of the function. This is the principal behind function minimization by gradient descent.
The general procedure is as follows:
For linear networks, the outputs, y_i, are direct functions of the inputs, x_j, and the weights, W_ij:
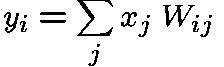
The error measure to be minimized for supervised learning is:
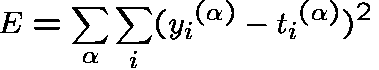
and the learning rule for a particular weight W_ij to the ith unit is:
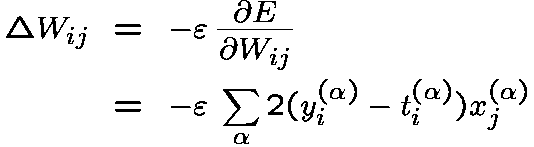
where epsilon is the learning rate, a small constant value.
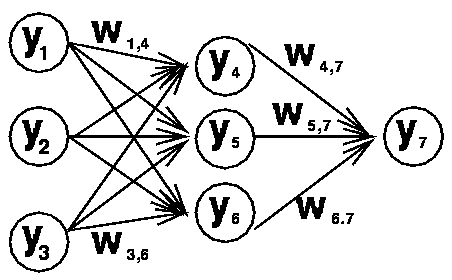
If we define the weight matrix from the first to the second layer as W_1 and the weight matrix from the second to the third layer as W_2:
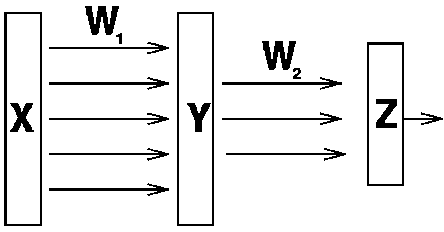
we can express the calculation performed by this network (i.e. the unit activations in each layer) as follows:
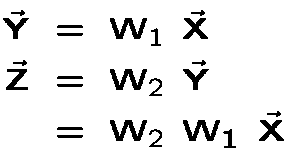
The product of two matrices, W_1 and W_2, is equal to a new matrix, W_3, so the above can be rewritten as:
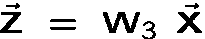
Thus, a multi-layer linear network is shown to be equivalent to a single layer linear network with the weight matrices collapsed into one matrix. The extra layers don't buy us anything in terms of solving hard problems.
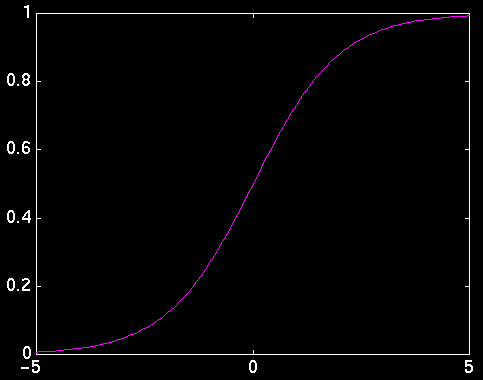

The derivative of the sigmoid function is:

This final form for the derivative is nice because it says that the derivative of the output of a unit with respect to its total input x can be expressed as a simple function of the unit's output f(x).
When we add the nonlinearity, the error function is the same as for the linear delta rule, but the activation is computed differently and this affects the weight update equations. To simplify the derivation of the weight updates (particularly for the multi-layer case), we define an intermediary term delta which is the derivative of the error with respect to a unit's total input x. For an output unit i:
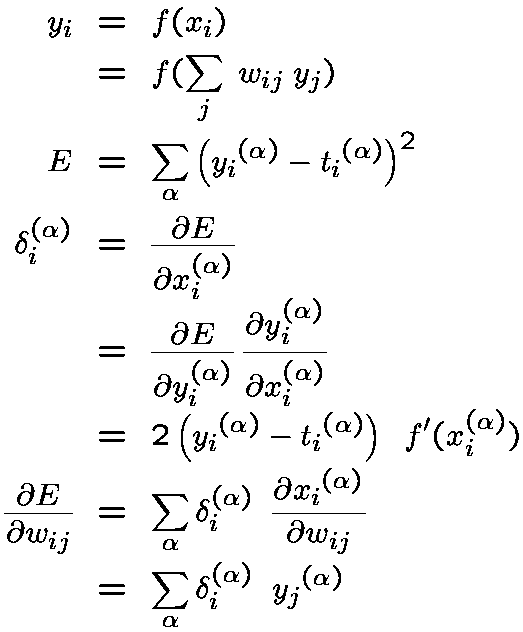

In the above equation, we have to sum over all output units i, because an incoming weight to a hidden unit j potentially affects the error of every output unit. So each hidden unit adds up the weighted sum of deltas being back-propagated along its outgoing connections to the output layer, multiplied by the weights on those connections. This weighted sum of deltas is then multiplied by the derivative of the sigmoid to get the hidden unit's own delta.
Once each unit (in any layer) has computed its own delta, it can obtain the weight update for each connection weight w_jk simply by multiplying the delta term by the incoming activation on that connection, y_k:

The back-propagation algorithm can be summarized as follows: For each training pattern, the network is activated and the target states are provided to the output units; for each output unit, the deltas are computed; for each hidden unit, the deltas are accumulated from the layer above to compute the hidden unit's delta; finally, for every unit in the network, the weight updates are computed.
If there is more than one hidden layer, each layer computes its deltas starting from the top layer down to the 2nd layer (one above the input layer). Once each layer's units have computed their deltas, they broadcast them by propagating them backwards on their incoming connections, multiplied by the incoming connection weights.
There are many heuristic solutions to the over-fitting problem, for example:

The learning rule now incorporates a weight shrinkage factor:
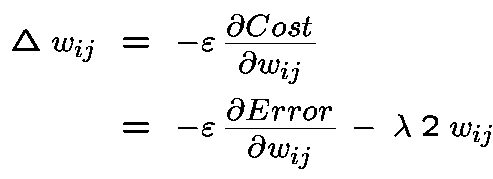
An effective technique for accelerating learning is to allow the weight changes to build up momentum, becoming steadily larger for weights that are making steady progress in one direction, but not for weight changes that oscillate (e.g. increase, then decrease, then increase again) from one pattern to the next. Momentum is implemented as follows: (where alpha is another learning constant that defines the rate of momentum): Define a momentum matrix the same size as the gradient matrix for each layer, initialized to all zeros. Each time the gradient is calculated, increment the momentum matrix in proportion to (1 - alpha) times the previous value of momentum, plus alpha times the gradient. The weight update is then the learning rate times the momentum. A good value for alpha is between 0.9 and 0.95.
Check out the following demo of steepest descent with and without momentum on a quadratic surface:
![[Previous]](prevsec.gif)
![[Parent]](parntsec.gif)
![[Next]](nextsec.gif)